
序列化总结
定义以及相关概念
序列化
将数据结构或者对象转成二进制串的过程
反序列化
将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程
序列化/反序列化的目的
- 永久的保存对象数据(将对象数据保存在文件当中,或者是磁盘中)
- 通过序列化操作将对象数据在网络上进行传输(由于网络传输是以字节流的方式对数据进行传输的.因此序列化的目的是将对象数据转换成字节流的形式)
- 将对象数据在进程之间进行传递(Activity之间传递对象数据时,需要在当前的Activity中对对象数据进行序列化操作.在另一个Activity中需要进行反序列化操作讲数据取出)
- Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长(即每个对象都在JVM中)但在现实应用中,就可能要停止JVM运行,但有要保存某些指定的对象,并在将来重新读取被保存的对象。这是Java对象序列化就能够实现该功能。(可选择入数据库、或文件的形式保存)
- 序列化对象的时候只是针对变量进行序列化,不针对方法进行序列化.
- 在Intent之间,基本的数据类型直接进行相关传递即可,但是一旦数据类型比较复杂的时候,就需要进行序列化操作了.
几种常见的序列化和反序列化协议
XML&SOAP
XML 是一种常用的序列化和反序列化协议,具有跨机器,跨语言等优点,SOAP(Simple Object Access protocol) 是一种被广泛应用的,基于 XML 为序列化和反序列化协议的结构化消息传递协议
JSON(Javascript Object Notation)
JSON 起源于弱类型语言 Javascript, 它的产生来自于一种称之为”Associative array”的概念,其本质是就是采用”Attribute-value”的方式来描述对象。实际上在 Javascript 和 PHP 等弱类型语言中,类的描述方式就是 Associative array。JSON 的如下优点,使得它快速成为最广泛使用的序列化协议之一。
这种 Associative array 格式非常符合工程师对对象的理解。
它保持了 XML 的人眼可读(Human-readable)的优点。
相对于 XML 而言,序列化后的数据更加简洁。 来自于的以下链接的研究表明:XML 所产生序列化之后文件的大小接近 JSON 的两倍
它具备 Javascript 的先天性支持,所以被广泛应用于 Web browser 的应用常景中,是 Ajax 的事实标准协议。
与 XML 相比,其协议比较简单,解析速度比较快。
松散的 Associative array 使得其具有良好的可扩展性和兼容性
Protobuf
Protobuf 具备了优秀的序列化协议的所需的众多典型特征。
标准的 IDL 和 IDL 编译器,这使得其对工程师非常友好。
序列化数据非常简洁,紧凑,与 XML 相比,其序列化之后的数据量约为 1/3 到 1/10。
解析速度非常快,比对应的 XML 快约 20-100 倍。
提供了非常友好的动态库,使用非常简介,反序列化只需要一行代码。
Serializable
Serializable 接口是一个标记接口,没有方法或字段。一旦实现了此接口,就标志该类的对象就是可序列化的。
- 声明一个实体类,实现 Serializable 接口;
- 使用 ObjectOutputStream 类的 writeObject 方法,实现序列化;
- 使用 ObjectInputStream 类的 readObject 方法,实现反序列化。
简单使用
1 | public class MainTest { |
如果 User 不实现 Serializable 接口而直接序列化会抛出 NotSerializableException 异常。
1 | Exception in thread "main" java.io.NotSerializableException: test.MainTest$User |
序列化版本号serialVersionUID
serialVersionUID 用来表明类的不同版本间的兼容性。如果你修改了此类, 要修改此值。否则以前用老版本的类序列化的类恢复时会报错: InvalidClassException
1 | Exception in thread "main" java.io.InvalidClassException: test.MainTest$User; local class incompatible: stream classdesc serialVersionUID = 12, local class serialVersionUID = 13 |
- 为了在反序列化时,确保类版本的兼容性,最好在每个要序列化的类中加入 private static final long serialVersionUID这个属性,具体数值自己定义。这样,即使某个类在与之对应的对象 已经序列化出去后做了修改,该对象依然可以被正确反序列化。否则,如果不显式定义该属性,这个属性值将由JVM根据类的相关信息计算,而修改后的类的计算 结果与修改前的类的计算结果往往不同,从而造成对象的反序列化因为类版本不兼容而失败。
- 不显式定义这个属性值的另一个坏处是,不利于程序在不同的JVM之间的移植。因为不同的编译器实现该属性值的计算策略可能不同,从而造成虽然类没有改变,但是因为JVM不同,出现因类版本不兼容而无法正确反序列化的现象出现。
- 因此 JVM 规范强烈 建议我们手动声明一个版本号,这个数字可以是随机的,只要固定不变就可以。同时最好是 private 和 final 的,尽量保证不变。
静态字段不会序列化
序列化时不保存静态变量,这是因为序列化保存的是对象的状态,静态变量属于类的状态,因此 序列化并不保存静态变量。
屏蔽字段:transient
transient 关键字有两个特性:
如果你不想让对象中的某个成员被序列化可以在定义它的时候加上 transient 关键字进行修饰,这样,在对象被序列化时其就不会被序列化。
transient 修饰过的成员反序列化后将赋予默认值,即 0 或 null。下面的 User 在反序列化后 password=null。
1
2
3
4
5class User implements Serializable {
public static String staticVar; // 不会序列化
public String name;
public transient String password; // 不会序列化
}
多引用写入
在默认情况下, 对于一个实例的多个引用,为了节省空间,只会写入一次,后面会追加几个字节代表某个实例的引用。
1 | ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("result.obj")); |
1 | User{name='laibinzhi', password='password'} |
成员变量的序列化
如果某个序列化类的成员变量是对象类型,则该对象类型的类必须实现序列化
1 | //没有实现Serializable |
运行结果
1 | Exception in thread "main" java.io.NotSerializableException: test.MainTest$Sub |
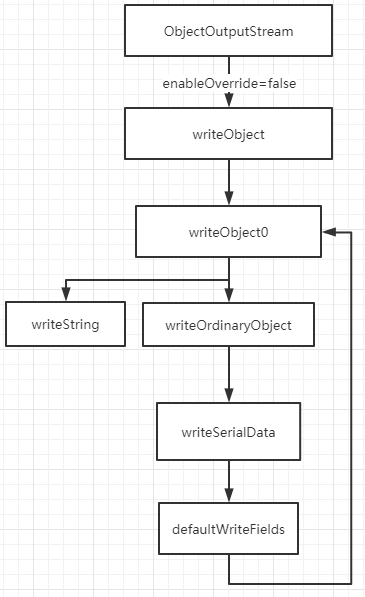
其实,这个可以在底层源码分析找到答案。一个对象序列化过程,会循环调用它的 Object 类型字段,递归调用序列化。也就是说,序列化 User 类的时候,会对 Sub 类进行序列化,但是对Teacher没有实现序列化接口。因此抛出 NotSerializableException 异常。所以如果某个实例化类的成员变量是对象类型,则该对象类型的类必须实现序列化。
1 | private void defaultWriteFields(Object obj, ObjectStreamClass desc) |
父类的序列化
情景:一个子类实现了 Serializable 接口,它的父类都没有实现 Serializable 接口,序列化该子类对象,然后反序列化后输出父类定义的某变量的数值,该变量数值与序列化时的数值不同。
解决: 要想将父类对象也序列化,就需要让父类也实现 Serializable 接口。如果父类不实现的话的,就 需要有默认的无参的构造函数。在父类没有实现 Serializable 接口时,虚拟机是不会序列化父对象的,而一个 Java 对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值。如果你考虑到这种序列化的情况,在父类无参构造函数中对变量进行初始化,否则的话,父类变量值都是默认声明的值,如 int 型的默认是 0,string 型的默认是 null。
注意:子类只可以序列化父类的可见属性,例如public,protected,或者其他情况,并且必须提供一个无参构造方法,否则会在运行时报错。
自定义序列化:readObject 和 writeObject
在序列化过程中,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化,如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。基于这个原理,可以在实际应用中得到使用,用于敏感字段的加密工作。
writeReplace先于writeObject
readResolve后于readObject
1 |
|
枚举类型
序列化Enum对象时,并不会保存元素的值,只会保存元素的name。这样,在不依赖元素值的前提下,ENUM对象如何更改都会保持兼容性。
单例模式下的序列化问题
单例类序列化,需要重写readResolve()方法;否则会破坏单例原则
Externalizable接口
1 | public interface Externalizable extends java.io.Serializable { |
和Serializable不同点:
- 序列化内容
Externalizable自定义序列化可以控制序列化的过程和决定哪些属性不被序列化。 - Serializable序列化时不会调用默认的构造器,而Externalizable序列化时会调用默认构造器的。
- 使用Externalizable时,必须按照写入时的确切顺序读取所有字段状态。否则会产生异常。例如,如果更改ExternalizableDemo类中的number和name属性的读取顺序,则将抛出java.io.EOFException。而Serializable接口没有这个要求。
Serializable原理和流程
https://blog.csdn.net/u011315960/article/details/89963230
Parcelable
定义和背景
Parcelable是AndroidSDK提供的,它是基于内存的,由于内存读写速度高于硬盘,因此Android中的跨进程对象的传递一般使用Parcelable。
简单使用
1 | class Student implements Parcelable { |
包含集合
1 | class Student implements Parcelable { |
kotlin中使用
官方文档https://developer.android.com/kotlin/parcelize?hl=zh-cn
1 | import kotlinx.parcelize.Parcelize |
为了启用Parcelable实现生成器(Parcelable implementation generator)的功能, 你需要在项目中应用Kotlin Android Extensions Gradle plugin, 实现这点只需要在模块的build.gradle中添加以下声明
1 | apply plugin: 'com.android.application' |
总结
Parcelable接口的实现类是可以通过Parcel写入和恢复数据的,并且必须要有一个非空的静态变量 CREATOR
Parcel
包装了我们需要传输的数据,然后在Binder中传输,也就是用于跨进程传输数据
简单来说,Parcel提供了一套机制,可以将序列化之后的数据写入到一个共享内存中,其他进程通过Parcel可以从这块共享内存中读出字节流,并反序列化成对象,下图是这个过程的模型。
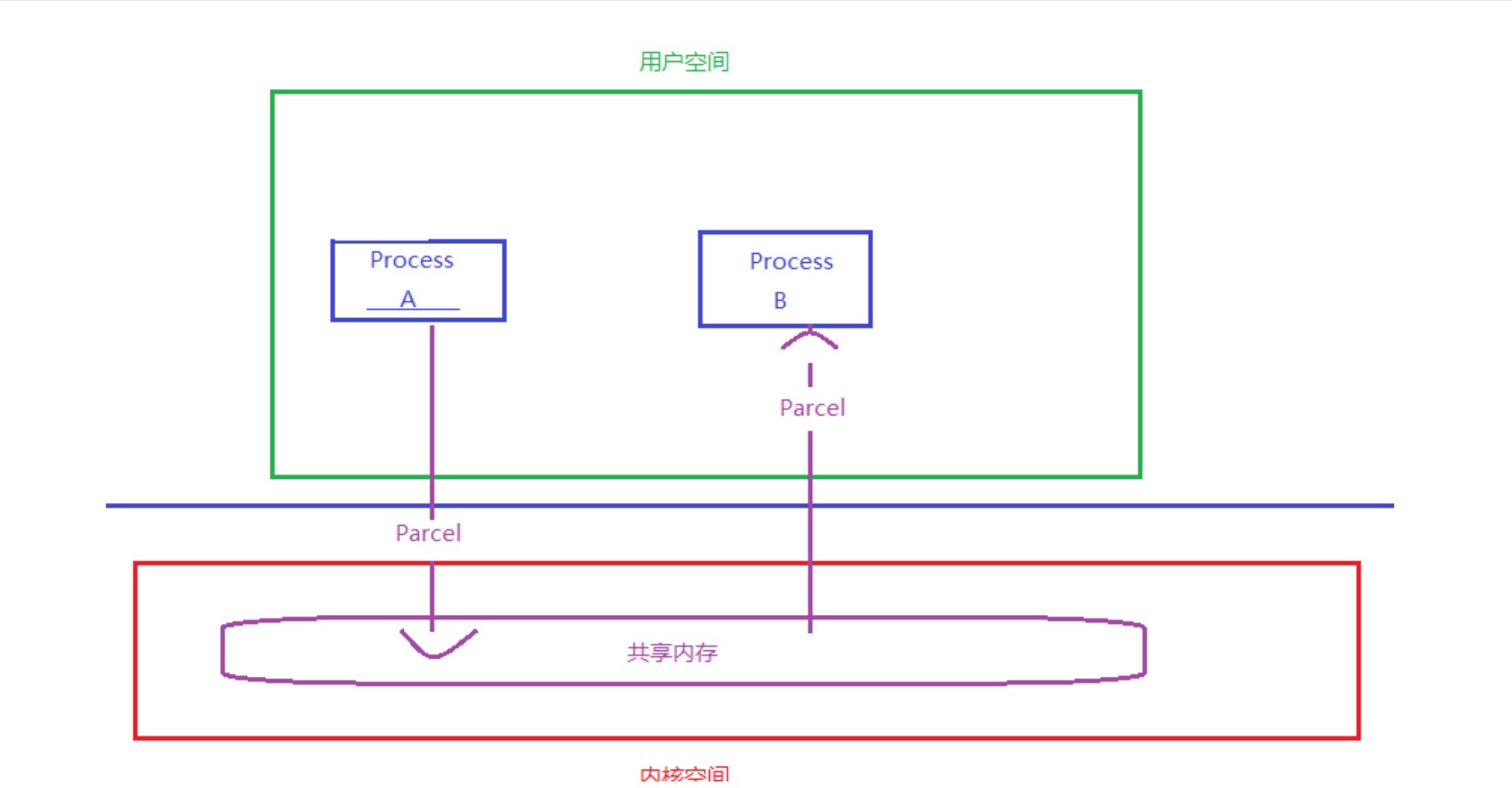
Parcel可以包含原始数据类型(用各种对应的方法写入,比如writeInt(),writeFloat()等),可以包含Parcelable对象,它还包含了一个活动的IBinder对象的引用,这个引用导致另一端接收到一个指向这个IBinder的代理IBinder。
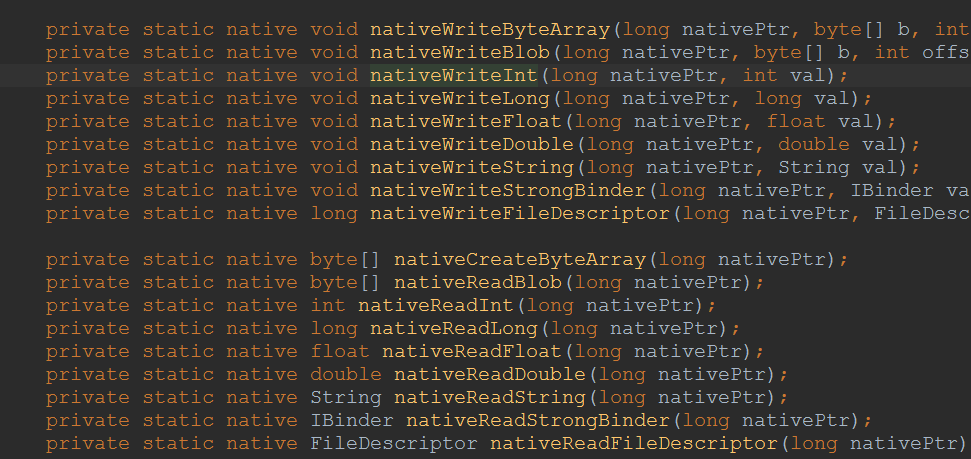
Parcelable通过Parcel实现了read和write的方法,从而实现序列化和反序列化
可以看出包含了各种各样的read和write方法,最终都是通过native方法实现
Parcelable实现过程
描述、序列化、反序列化
Parcelable与Serializable的性能比较
Serializable性能分析
- Serializable在序列化过程中会创建大量的临时变量,这样就会造成大量的GC。
- Serializable使用了大量反射,而反射操作耗时。
- Serializable使用了大量的IO操作,也影响了耗时。
Parcelable性能分析
Parcelable则是以IBinder作为信息载体,在内存上开销比较小,因此在内存之间进行数据传递时,推荐使用Parcelable,而Parcelable对数据进行持久化或者网络传输时操作复杂,一般这个时候推荐使用Serializable。
性能比较总结描述
- 在内存的使用中,Parcelable在性能方面要强于Serializable
- Serializable在序列化操作的时候会产生大量的临时变量,(原因是使用了反射机制)从而导致GC的频繁调用,因此在性能上会稍微逊色
- Parcelable是以Ibinder作为信息载体的.在内存上的开销比较小,因此在内存之间进行数据传递的时候,Android推荐使用Parcelable,既然是内存方面比价有优势,那么自然就要优先选择.
- 在读写数据的时候,Parcelable是在内存中直接进行读写,而Serializable是通过使用IO流的形式将数据读写入在硬盘上.但是:虽然Parcelable的性能要强于Serializable,但是仍然有特殊的情况需要使用Serializable,而不去使用Parcelable,因为Parcelable无法将数据进行持久化,因此在将数据保存在磁盘的时候,仍然需要使用Serializable,因为Parcelable无法很好的将数据进行持久化.(原因是在不同的Android版本当中,Parcelable 可能会不同,因此数据的持久化方面仍然是使用Serializable)
两种如何选择
- 在使用内存方面,Parcelable比Serializable性能高,所以推荐使用Parcelable。
- Serializable在序列化的时候会产生大量的临时变量,从而引起频繁的GC。
- Parcelable不能使用在要将数据存储在磁盘上的情况,因为Parcelable不能很好的保证数据的持续性,在外界有变化的情况下,建议使用Serializable
相关考题
Android里面为什么要设计出Bundle而不是直接用Map结构
Bundle内部是由ArrayMap实现的,ArrayMap的内部实现是两个数组,一个int数组是存储对象数据对应下标,一个对象数组保存key和value,内部使用二分法对key进行排序,所以在添加、删除、查找数据的时候,都会使用二分法查找,只适合于小数据量操作, 如果在数据量比较大的情况下,那么它的性能将退化。而HashMap内部则是数组+链表结构,所以在数据量较少的时候,HashMap的EntryArray比ArrayMap占用更多的内存。因为使用Bundle的场景大多数为小数据量,我没见过在两个Activity之间传递10个以上数据的场景,所以相比之下,在这种情况下使用ArrayMap保存数据,在操作速度和内存占用上都具有优势,因此使用Bundle来传递数据,可以保证更快的速度和更少的内存占用。
另外一个原因,则是在Android中如果使用Intent来携带数据的话,需要数据是基本类型或者是可序列化类型,HashMap使用Serializable进行序列化,而Bundle则是使用Parcelable进行序列化。而在Android平台中,更推荐使用Parcelable实现序列化,虽然写法复杂,但是开销更小,所以为了更加快速的进行数据的序列化和反序列化,系统封装了Bundle类,方便我们进行数据的传输。Android中Intent/Bundle的通信原理及大小限制
Intent中的Bundle是使用Binder机制进行数据传送的。能使用的Binder的缓冲区是有大小限制的(有些手机是2M),而一个进程默认有16个Binder线程,所以一个线程能占用的缓冲区就更小了(有人以前做过测试,大约一个线程可以占用128KB)。所以当你看到TheBinder transactionfailedbecauseitwastoolarge这类TransactionTooLargeException异常时,你应该知道怎么解决了
为何Intent不能直接在组件间传递对象而要通过序列化机制?
Intent在启动其他组件时,会离开当前应用程序进程,进入ActivityManagerService进程
(intent.prepareToLeaveProcess()),这也就意味着,Intent所携带的数据要能够在不同进程间传输。首先我们知道,Android是基于Linux系统,不同进程之间的java对象是无法传输,所以我们此处要对对象进行序列化,从而实现对象在应用程序进程和ActivityManagerService进程之间传输。
而Parcel或者Serializable都可以将对象序列化,其中,Serializable使用方便,但性能不如Parcel 容器,后者也是Android系统专门推出的用于进程间通信等的接口
