
性能优化-ANR
概念
ANR(Application Not responding),是指应用程序未响应,Android系统对于一些事件需要在一定的时间范围内完成,如果超过预定时间能未能得到有效响应或者响应时间过长,都会造成ANR
在 Android 里,应用程序的响应性是由 Activity Manager 和 WindowManager 系统服务监视的。当它监测到以下情况中的一个时,Android 就会针对特定的应用程序显示 ANR:
场景
Service Timeout
前台Service:
onCreate,onStart,onBind等生命周期在20s内没有处理完成发生ANR。
后台Service:onCreate,onStart,onBind等生命周期在200s内没有处理完成发生ANR
logcat日志关键字:Timeout executing serviceBroadcastQueue Timeout
前台Broadcast:onReceiver在
10S内没有处理完成发生ANR。
后台Broadcast:onReceiver在60s内没有处理完成发生ANR。
logcat日志关键字:Timeout of broadcast BroadcastRecordContentProvider Timeout
ContentProvider 在
10S内没有处理完成发生ANR。 logcat日志关键字:timeout publishing content providersInputDispatching Timeout
input事件在
5S内没有处理完成发生了ANR。
logcat日志关键字:Input event dispatching timed out
ANR出现的原因
- 主线程频繁进行耗时的IO操作:如数据库读写
- 多线程操作的死锁,主线程被block;
- 主线程被Binder 对端block;
System Server中WatchDog出现ANR;service binder的连接达到上线无法和和System Server通信- 系统资源已耗尽(管道、CPU、IO)
ANR触发机制
ANR是一套监控Android应用响应是否及时的机制,可以把发生ANR比作是引爆炸弹,那么整个流程包含三部分组成:
- 埋定时炸弹:中控系统(system_server进程)启动倒计时,在规定时间内如果目标(应用进程)没有干完所有的活,则中控系统会定向炸毁(杀进程)目标。
- 拆炸弹:在规定的时间内干完工地的所有活,并及时向中控系统报告完成,请求解除定时炸弹,则幸免于难。
- 引爆炸弹:中控系统立即封装现场,抓取快照,搜集目标执行慢的罪证(traces),便于后续的案件侦破(调试分析),最后是炸毁目标。
常见的ANR有service、broadcast、provider以及input
service超时机制
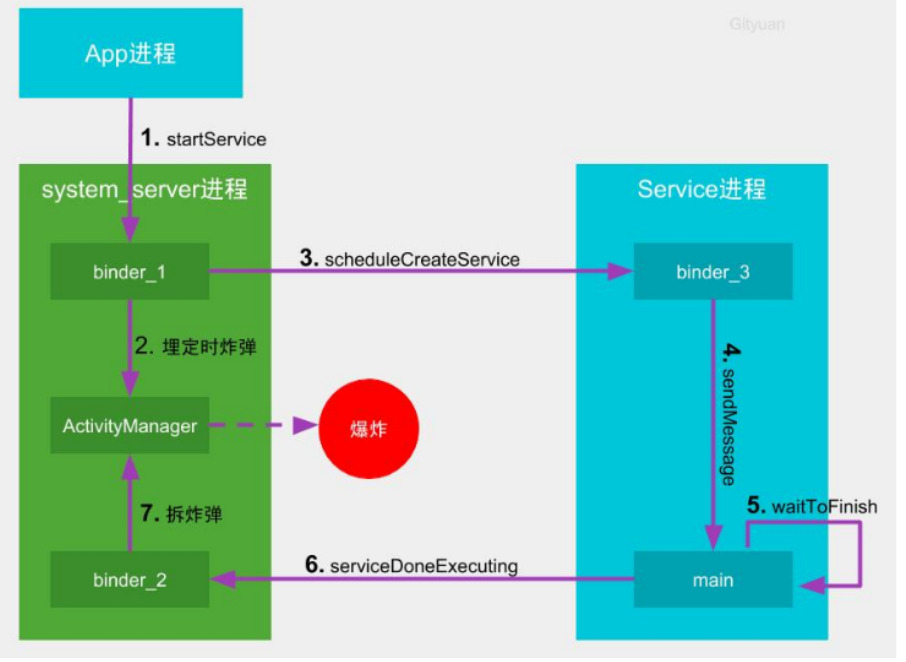
- 客户端(App进程)向中控系统(system_server进程)发起启动服务的请求
- 中控系统派出一名空闲的通信员(binder_1线程)接收该请求,紧接着向组件管家(ActivityManager线程)发送消息,埋下定时炸弹
- 通讯员1号(binder_1)通知工地(service所在进程)的通信员准备开始干活
- 通讯员3号(binder_3)收到任务后转交给包工头(main主线程),加入包工头(main主线程)的任务队列(MessageQueue)
- 包工头(main主线程)经过一番努力干完活(完成service启动的生命周期),然后等待SharedPreferences(简称SP)的持久化;
- 包工头在SP执行完成后,立刻向中控系统汇报工作已完成
- 中控系统的通讯员2号(binder_2)收到包工头的完工汇报后,立刻拆除炸弹。如果在炸弹倒计时结束前拆除炸弹则相安无事,否则会引发爆炸(触发ANR)
broadcast超时机制
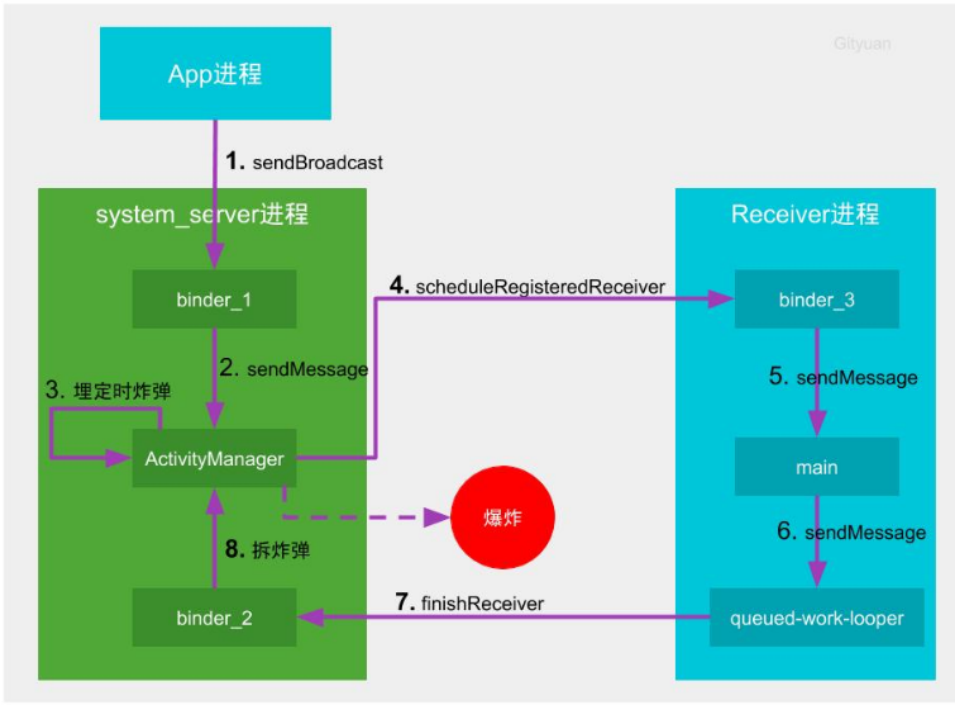
- 客户端(App进程)向中控系统(system_server进程)发起发送广播的请求
- 中控系统派出一名空闲的通信员(binder_1)接收该请求转交给组件管家(ActivityManager线程)
- 组件管家执行任务(processNextBroadcast方法)的过程埋下定时炸弹
- 组件管家通知工地(receiver所在进程)的通信员准备开始干活
- 通讯员3号(binder_3)收到任务后转交给包工头(main主线程),加入包工头的任务队列(MessageQueue)
- 包工头经过一番努力干完活(完成receiver启动的生命周期),发现当前进程还有SP正在执行写入文件的操作,便将向中控系统汇报的任务交给SP工人(queued-work-looper线程)
- SP工人历经艰辛终于完成SP数据的持久化工作,便可以向中控系统汇报工作完成
- 中控系统的通讯员2号(binder_2)收到包工头的完工汇报后,立刻拆除炸弹。如果在倒计时结束前拆除炸弹则相安无事,否则会引发爆炸(触发ANR)
(说明:SP从8.0开始采用名叫“queued-work-looper”的handler线程,在老版本采用newSingleThreadExecutor创建的单线程的线程池)
如果是动态广播,或者静态广播没有正在执行持久化操作的SP任务,则不需要经过“queued-work-looper”线程中转,而是直接向中控系统汇报,流程更为简单,如下图所示:
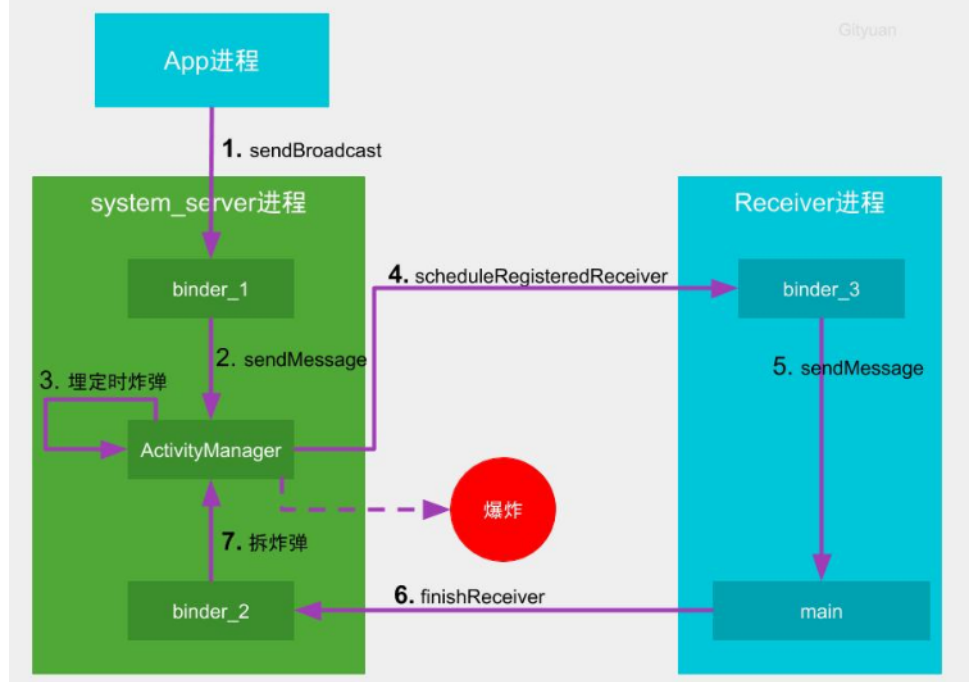
可见,只有XML静态注册的广播超时检测过程会考虑是否有SP尚未完成,动态广播并不受其影响。SP的apply将修改的数据项更新到内存,然后再异步同步数据到磁盘文件,因此很多地方会推荐在主线程调用采用apply方式,避免阻塞主线程,但静态广播超时检测过程需要SP全部持久化到磁盘,如果过度使用apply会增大应用ANR的概率,Google这样设计的初衷是针对静态广播的场景下,保障进程被杀之前一定能完成SP的数据持久化。因为在向中控系统汇报广播接收者工作执行完成前,该进程的优先级为Foreground级别,高优先级下进程不但不会被杀,而且能分配到更多的CPU时间片,加速完成SP持久化。
provider超时机制
provider的超时是在provider进程首次启动的时候才会检测,当provider进程已启动的场景,再次请求provider并不会触发provider超时。
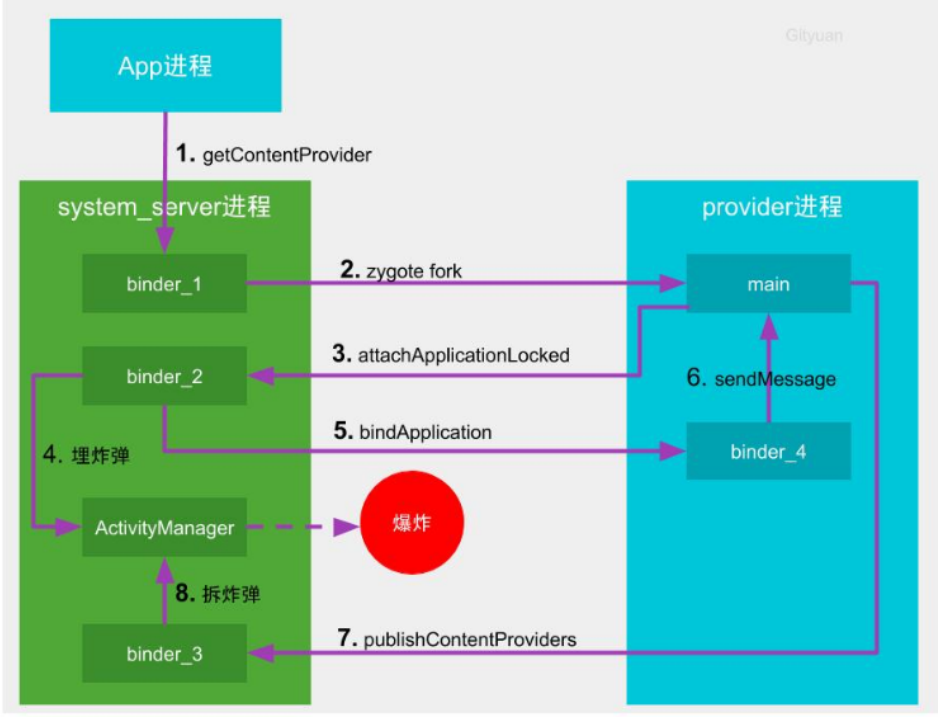
- 客户端(App进程)向中控系统(system_server进程)发起获取内容提供者的请求
- 中控系统派出一名空闲的通信员(binder_1)接收该请求,检测到内容提供者尚未启动,则先通过zygote孵化新进程
- 新孵化的provider进程向中控系统注册自己的存在
- 中控系统的通信员2号接收到该信息后,向组件管家(ActivityManager线程)发送消息,埋下炸弹
- 通信员2号通知工地(provider进程)的通信员准备开始干活
- 通讯员4号(binder_4)收到任务后转交给包工头(main主线程),加入包工头的任务队列(MessageQueue)
- 包工头经过一番努力干完活(完成provider的安装工作)后向中控系统汇报工作已完成
- 中控系统的通讯员3号(binder_3)收到包工头的完工汇报后,立刻拆除炸弹。如果在倒计时结束前拆除炸弹则相安无事,否则会引发爆炸(触发ANR)
input超时机制
input的超时检测机制跟service、broadcast、provider截然不同,为了更好的理解input过程先来介绍两个重要线程的相关工作:
InputReader线程负责通过EventHub(监听目录/dev/input)读取输入事件,一旦监听到输入事件则放入到InputDispatcher的mInBoundQueue队列,并通知其处理该事件;
InputDispatcher线程负责将接收到的输入事件分发给目标应用窗口,分发过程使用到3个事件队列:
- mInBoundQueue用于记录InputReader发送过来的输入事件;
- outBoundQueue用于记录即将分发给目标应用窗口的输入事件;
- waitQueue用于记录已分发给目标应用,且应用尚未处理完成的输入事件;
input的超时机制并非时间到了一定就会爆炸,而是处理后续上报事件的过程才会去检测是否该爆炸,所以更像是扫雷的过程,具体如下图所示。
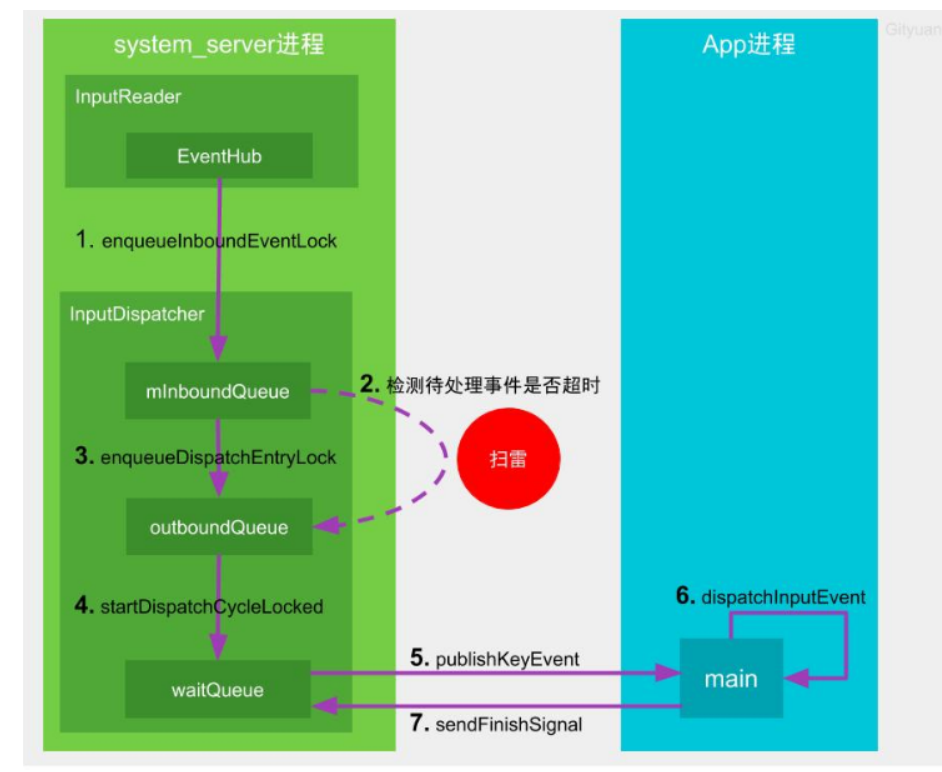
InputReader线程通过EventHub监听底层上报的输入事件,一旦收到输入事件则将其放至mInBoundQueue队列,并唤醒InputDispatcher线程
InputDispatcher开始分发输入事件,设置埋雷的起点时间。先检测是否有正在处理的事件(mPendingEvent),如果没有则取出mInBoundQueue队头的事件,并将其赋值给mPendingEvent,且重置ANR的timeout;否则不会从mInBoundQueue中取出事件,也不会重置timeout。然后检查窗口是否就绪(checkWindowReadyForMoreInputLocked),满足以下任一情况,则会进入扫雷状态(检测前一个正在处理的事件是否超时),终止本轮事件分发,否则继续执行步骤3。
- 对于按键类型的输入事件,则outboundQueue或者waitQueue不为空,
- 对于非按键的输入事件,则waitQueue不为空,且等待队头时间超时500ms
当应用窗口准备就绪,则将mPendingEvent转移到outBoundQueue队列
当outBoundQueue不为空,且应用管道对端连接状态正常,则将数据从outboundQueue中取出事件,放入waitQueue队列
InputDispatcher通过socket告知目标应用所在进程可以准备开始干活
App在初始化时默认已创建跟中控系统双向通信的socketpair,此时App的包工头(main线程)收到输入事件后,会层层转发到目标窗口来处理
包工头完成工作后,会通过socket向中控系统汇报工作完成,则中控系统会将该事件从waitQueue队列中移除。
input超时机制为什么是扫雷,而非定时爆炸呢?是由于对于input来说即便某次事件执行时间超过timeout时长,只要用户后续在没有再生成输入事件,则不会触发ANR。 这里的扫雷是指当前输入系统中正在处理着某个耗时事件的前提下,后续的每一次input事件都会检测前一个正在处理的事件是否超时(进入扫雷状态),检测当前的时间距离上次输入事件分发时间点是否超过timeout时长。如果前一个输入事件,则会重置ANR的timeout,从而不会爆炸。
Timeout时长
对于前台服务,则超时为SERVICE_TIMEOUT = 20s;
对于后台服务,则超时为SERVICE_BACKGROUND_TIMEOUT = 200s
对于前台广播,则超时为BROADCAST_FG_TIMEOUT = 10s;
对于后台广播,则超时为BROADCAST_BG_TIMEOUT = 60s;
ContentProvider超时为CONTENT_PROVIDER_PUBLISH_TIMEOUT = 10s;
InputDispatching Timeout: 输入事件分发超时5s,包括按键和触摸事件。
注意事项: Input的超时机制与其他的不同,对于input来说即便某次事件执行时间超过timeout时长,只要用户后续在没有再生成输入事件,则不会触发ANR
超时检测机制
Service超时检测机制:
- 超过一定时间没有执行完相应操作来触发移除延时消息,则会触发anr;
BroadcastReceiver超时检测机制:
- 有序广播的总执行时间超过 2* receiver个数 * timeout时长,则会触发anr;
有序广播的某一个receiver执行过程超过 timeout时长,则会触发anr;
- 有序广播的总执行时间超过 2* receiver个数 * timeout时长,则会触发anr;
另外:
- 对于Service, Broadcast, Input发生ANR之后,最终都会调用AMS.appNotResponding;
- 对于provider,在其进程启动时publish过程可能会出现ANR, 则会直接杀进程以及清理相应信息,而不会弹出ANR的对话框
如何避免 ANR?
考虑上面的 ANR 定义,让我们来研究一下为什么它会在 Android 应用程序里发生和如何最佳
构建应用程序来避免 ANR。
Android 应用程序通常是运行在一个单独的线程(例如,main)里。这意味着你的应用程序
所做的事情如果在主线程里占用了太长的时间的话,就会引发 ANR 对话框,因为你的应用程
序并没有给自己机会来处理输入事件或者 Intent 广播。因此,运行在主线程里的任何方法都尽可能少做事情。特别是,Activity 应该在它的关键
生命周期方法(如 onCreate()和 onResume())里尽可能少的去做创建操作。潜在的耗时操
作,例如网络或数据库操作,或者高耗时的计算如改变位图尺寸,应该在子线程里(或者以
数据 库操作为例,通过异步请求的方式)来完成。然而,不是说你的主线程阻塞在那里等
待子线程的完成——也不是调用 Thread.wait()或是 Thread.sleep()。替代的方法是,主
线程应该为子线程提供一个 Handler,以便完成时能够提交给主线程。以这种方式设计你的
应用程序,将 能保证你的主线程保持对输入的响应性并能避免由于 5 秒输入事件的超时引
发的 ANR 对话框。这种做法应该在其它显示 UI 的线程里效仿,因为它们都受相同的超 时影
响。IntentReceiver 执行时间的特殊限制意味着它应该做:在后台里做小的、琐碎的工作如保
存设定或者注册一个 Notification。和在主线 程里调用的其它方法一样,应用程序应该避
免在 BroadcastReceiver 里做耗时的操作或计算。但不再是在子线程里做这些任务(因为
BroadcastReceiver 的生命周期短),替代的是,如果响应 Intent 广播需要执行一个耗时
的动作的话,应用程序应该启动一个 Service。顺便提及一句,你也应该避免在IntentReceiver 里启动一个 Activity,因为它会创建一个新的画面,并从当前用户正在运行的程序上抢夺焦点。如果你的应用程序在响应 Intent 广播时需要向用户展示什么,你应该使用 Notification Manager 来实现。增强响应灵敏性
一般来说,在应用程序里,100 到 200ms 是用户能感知阻滞的时间阈值。因此,这里有一些
额外的技巧来避免 ANR,并有助于让你的应用程序看起来有响应性。
如果你的应用程序为响应用户输入正在后台工作的话,可以显示工作的进度(ProgressBar
和 ProgressDialog 对这种情况来说很有用)。
特别是游戏,在子线程里做移动的计算。
如果你的应用程序有一个耗时的初始化过程的话,考虑可以显示一个 SplashScreen 或者快
速显示主画面并异步来填充这些信息。在这两种情况下,你都应该显示正在进行的进度,以
免用户认为应用程序被冻结了。
前台与后台ANR【了解下就行】
前台ANR:用户能感知,比如拥有前台可见的activity的进程,或者拥有前台通知的fg-service的进程,此时发生ANR对用户体验影响比较大,需要弹框让用户决定是否退出还是等待
后台ANR:,只抓取发生无响应进程的trace,也不会收集CPU信息,并且会在后台直接杀掉该无响应的进程,不会弹框提示用户
如何避免ANR发生
- 主线程尽量只做UI相关的操作,避免耗时操作,比如过度复杂的UI绘制,网络操作,文件IO操作;
- 避免主线程跟工作线程发生锁的竞争,减少系统耗时binder的调用,谨慎使用sharePreference,注意主线程执行provider query操作
总之,尽可能减少主线程的负载,让其空闲待命,以期可随时响应用户的操作
ANR分析
概述
前台ANR发生后,系统会马上去抓取现场的信息,用于调试分析,收集的信息如下:
- 将am_anr信息输出到EventLog,也就是说ANR触发的时间点最接近的就是EventLog中输出的am_anr信息
- 收集以下重要进程的各个线程调用栈trace信息,保存在data/anr/traces.txt文件
- 当前发生ANR的进程,system_server进程以及所有persistent进程
- audioserver, cameraserver, mediaserver, surfaceflinger等重要的native进程
- CPU使用率排名前5的进程
- 将发生ANR的reason以及CPU使用情况信息输出到main log
- 将traces文件和CPU使用情况信息保存到dropbox,即data/system/dropbox目录
- 对用户可感知的进程则弹出ANR对话框告知用户,对用户不可感知的进程发生ANR则直接杀掉
分析步骤
- 定位发生ANR时间点
- 查看trace信息
- 分析是否有耗时的message,binder调用,锁的竞争,CPU资源的抢占
- 结合具体的业务场景的上下文来分析
分析技巧
- 通过logcat日志,traces文件确认anr发生时间点
- traces文件和CPU使用率
- /data/anr/traces.txt
- 主线程状态
- 其他线程状态
关键信息
- main:main标识是主线程,如果是线程,那么命名成“Thread-X”的格式,x表示线程id,逐步递增。
- prio:线程优先级,默认是5
- tid:tid不是线程的id,是线程唯一标识ID
- group:是线程组名称
- sCount:该线程被挂起的次数
- dsCount:是线程被调试器挂起的次数
- obj:对象地址
- self:该线程Native的地址
- sysTid:是线程号(主线程的线程号和进程号相同)
- nice:是线程的调度优先级
- sched:分别标志了线程的调度策略和优先级
- cgrp:调度归属组
- handle:线程处理函数的地址。
- state:是调度状态
- schedstat:从 /proc/[pid]/task/[tid]/schedstat读出,三个值分别表示线程在cpu上执行的时间、线程的等待时间和线程执行的时间片长度,不支持这项信息的三个值都是0;
- utm:是线程用户态下使用的时间值(单位是jiffies)
- stm:是内核态下的调度时间值
- core:是最后执行这个线程的cpu核的序号
ANR监控方案
1. FileObserver
Android系统在此基础上封装了一个FileObserver类来方便使用Inotify机制。FileObserver是一个抽象类,需要定义子类实现该类的onEvent抽象方法,当被监控的文件或者目录发生变更事件时,将回调FileObserver的onEvent()函数来处理文件或目录的变更事件
1 | package com.test.arch_demo.anr; |
2. watchDog
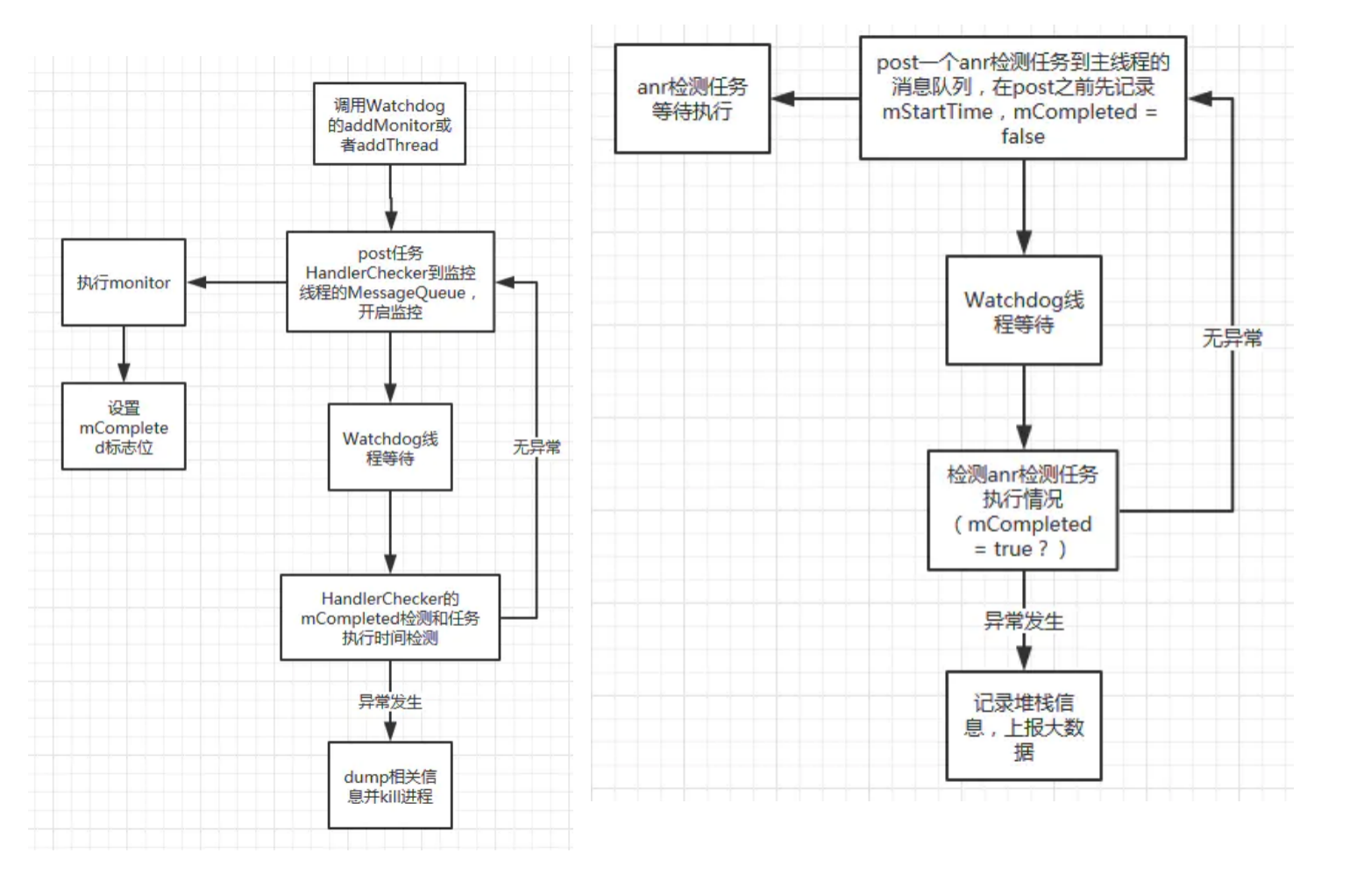
trace.txt文件解读
- 人为的收集trace.txt的命令
adb shell kill -3 888 //可指定进程pid
执行完该命令后traces信息的结果保存到文件/data/anr/traces.txt - trace文件解读
1 | ----- pid 888 at 2016-11-11 22:22:22 ----- |
- trace参数解读
1 | "Binder_1" prio=5 tid=8 Native |
第0行:
- 线程名: Binder_1(如有daemon则代表守护线程)
- prio: 线程优先级
- tid: 线程内部id
- 线程状态: NATIVE
第1行:
- group: 线程所属的线程组
- sCount: 线程挂起次数
- dsCount: 用于调试的线程挂起次数
- obj: 当前线程关联的java线程对象
- self: 当前线程地址
第2行:
- sysTid:线程真正意义上的tid
- nice: 调度有优先级
- cgrp: 进程所属的进程调度组
- sched: 调度策略
- handle: 函数处理地址
第3行:
- state: 线程状态
- schedstat: CPU调度时间统计
- utm/stm: 用户态/内核态的CPU时间(单位是jiffies)
- core: 该线程的最后运行所在核
- HZ: 时钟频率
第4行:
- stack:线程栈的地址区间
- stackSize:栈的大小
第5行:
- mutex: 所持有mutex类型,有独占锁exclusive和共享锁shared两类
schedstat含义说明:
nice值越小则优先级越高。此处nice=-2, 可见优先级还是比较高的;
schedstat括号中的3个数字依次是Running、Runable、Switch,紧接着的是utm和stm
- Running时间:CPU运行的时间,单位ns
- Runable时间:RQ队列的等待时间,单位ns
- Switch次数:CPU调度切换次数
- utm: 该线程在用户态所执行的时间,单位是jiffies,jiffies定义为sysconf(_SC_CLK_TCK),默认等于10ms
- stm: 该线程在内核态所执行的时间,单位是jiffies,默认等于10ms
可见,该线程Running=186667489018ns,也约等于186667ms。在CPU运行时间包括用户态(utm)和内核态(stm)。 utm + stm = (12112 + 6554) ×10 ms = 186666ms。
结论:utm + stm = schedstat第一个参数值。
ANR 案例整理
一、主线程被其他线程lock,导致死锁
1 | waiting on <0x1cd570> (a android.os.MessageQueue) |
二、主线程做耗时的操作:比如数据库读写。
1 | "main" prio=5 tid=1 Native |
三、binder数据量过大
1 | 07-21 04:43:21.573 1000 1488 12756 E Binder : Unreasonably large binder reply buffer: on android.content.pm.BaseParceledListSlice$1@770c74f calling 1 size 388568 (data: 1, 32, 7274595) |
四、binder 通信失败
1 | 07-21 06:04:35.580 <6>[32837.690321] binder: 1698:2362 transaction failed 29189/-3, size 100-0 line 3042 |
